Demander de l'aide à une IA à propos cet article :
Sommaire
Sommaire
Imaginez pouvoir discuter avec l'ensemble de votre documentation d'entreprise comme si vous parliez à un collègue expert. Vos PDF, vos archives d'emails, vos rapports internes... tous accessibles instantanément à travers une simple conversation avec une IA. C'est exactement ce que permet un système RAG (Retrieval Augmented Generation) sur n8n.
Dans ce guide pratique, je vais vous montrer comment créer votre propre chatbot intelligent connecté à vos connaissances d'entreprise, sans hallucinations, avec uniquement des sources vérifiées. Que vous soyez entrepreneur, développeur ou responsable IT, vous découvrirez comment transformer votre documentation en un assistant IA fonctionnel.
RAG : Qu'est-ce que c'est et pourquoi l'utiliser ?
Le RAG (Retrieval Augmented Generation) représente une avancée majeure dans le domaine de l'intelligence artificielle conversationnelle. Contrairement aux chatbots classiques qui s'appuient uniquement sur leur entraînement initial, un système RAG va chercher des informations pertinentes dans votre propre base de données avant de générer une réponse.
Comment fonctionne concrètement un RAG ? Le processus se déroule en trois étapes simples : d'abord, votre question est transformée en vecteur mathématique (embedding). Ensuite, le système recherche dans votre base de connaissances les documents les plus similaires à votre question. Enfin, l'IA génère une réponse en se basant exclusivement sur ces documents récupérés.
Pourquoi utiliser n8n pour créer votre RAG ? n8n offre une interface visuelle intuitive qui rend l'automatisation accessible même sans compétences avancées en programmation. Vous créez votre workflow par simple glisser-déposer, vous visualisez chaque étape du processus, et vous pouvez facilement intégrer vos outils existants (Google Drive, Notion, bases de données...). De plus, n8n peut être auto-hébergé, ce qui vous donne un contrôle total sur vos données sensibles.
La combinaison n8n + Qdrant (ou Pinecone) + OpenAI/Ollama vous permet de construire une solution professionnelle sans les coûts exorbitants des solutions SaaS tout-en-un. Vous gardez la maîtrise technique et vous pouvez adapter le système exactement à vos besoins.
Les avantages d'un système RAG pour votre entreprise
Éliminer les hallucinations de l'IA constitue le premier bénéfice majeur. Avec un RAG, votre IA ne peut répondre qu'en se basant sur vos documents réels. Fini les réponses inventées ou approximatives : chaque information provient d'une source vérifiable que vous avez vous-même fournie.
Créer une mémoire organisationnelle devient possible. Imaginez : tous vos guides internes, vos procédures, vos comptes-rendus de réunion, vos études de marché... accessibles en quelques secondes via une simple question en langage naturel. Un nouveau collaborateur peut interroger le système sur "comment gérer une réclamation client" et obtenir instantanément la procédure exacte, extraite de votre documentation officielle.
Gagner un temps considérable sur les recherches d'information. Plus besoin de fouiller dans des dizaines de dossiers partagés ou de solliciter constamment vos collègues pour retrouver un document. Le RAG indexe automatiquement vos connaissances et les rend interrogeables instantanément.
Maintenir la confidentialité de vos données reste garanti, surtout si vous optez pour une solution auto-hébergée avec Ollama plutôt qu'OpenAI. Vos documents sensibles ne quittent jamais votre infrastructure.
La scalabilité représente également un atout non négligeable : commencez avec quelques PDF, puis ajoutez progressivement vos emails, vos tickets de support, vos bases de connaissances. Le système grandit avec vous.
Créer un RAG sur n8n étape par étape :
Passons maintenant à la pratique. Je vais vous guider à travers chaque étape de la création de votre système RAG fonctionnel.
Prérequis et configuration initiale
Avant de commencer, vous devez mettre en place votre environnement technique. Installez n8n sur votre machine ou un serveur. Si vous cherchez un hébergement performant pour n8n, j'ai rédigé un guide des meilleurs VPS pour n8n qui compare les solutions selon vos besoins et votre budget.
Choisissez votre base de données vectorielle : je recommande fortement Qdrant Cloud plutôt qu'une installation self-hosted. Pourquoi ? Parce que Qdrant Cloud vous offre une infrastructure prête à l'emploi en quelques minutes, sans vous soucier de la configuration Docker, des mises à jour ou de la maintenance. C'est plus rapide, plus pratique, et leur offre gratuite est largement suffisante pour débuter (1 Go de stockage vectoriel gratuit, soit des milliers de documents).
Créez votre compte Qdrant Cloud en quelques étapes :
Rendez-vous sur cloud.qdrant.io et créez un compte
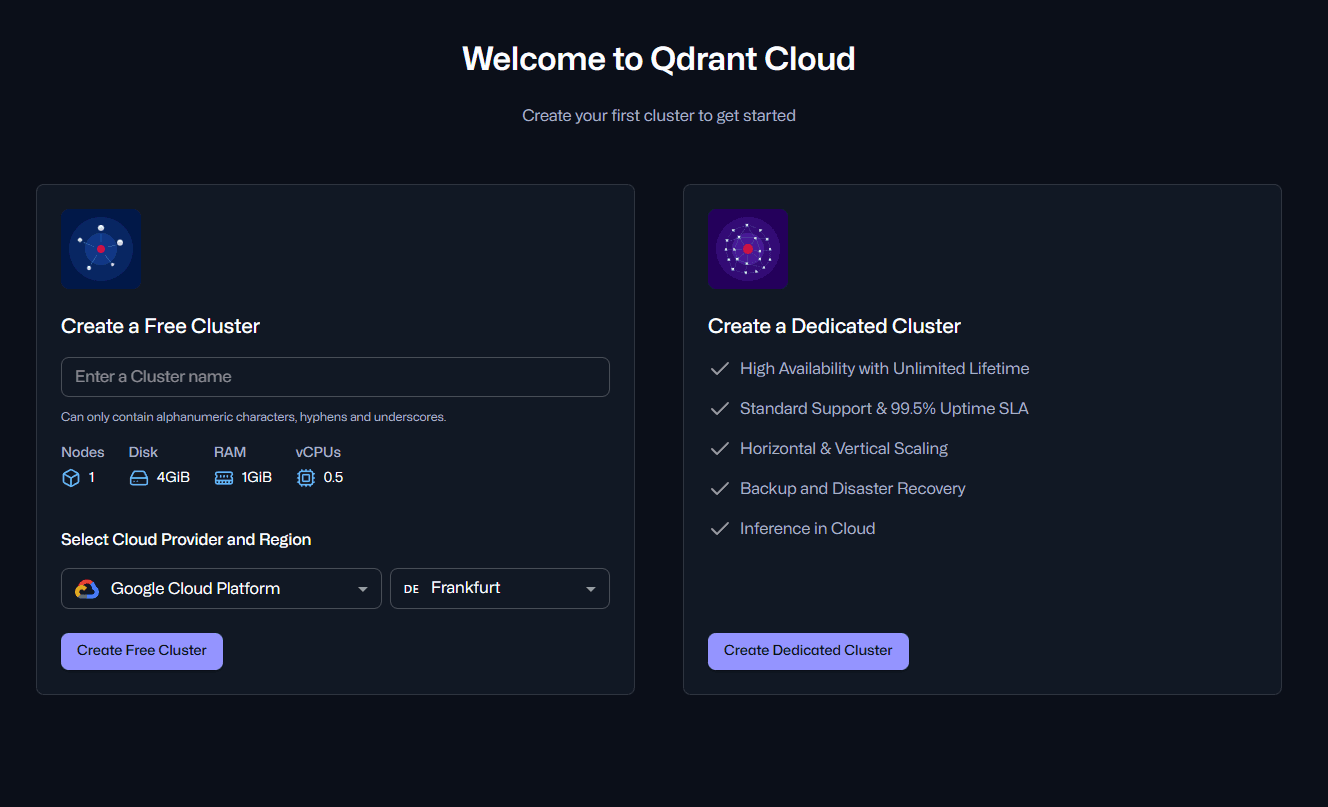
Créez un nouveau cluster (choisissez la région la plus proche de vous pour minimiser la latence)
Notez précieusement votre URL de cluster (ressemble à
https://xxxxx-xxxxx.eu-central.aws.cloud.qdrant.io:6333)Générez une clé API depuis l'interface (section "Data Access Control" ou "API Keys")
Configurer Qdrant : Collection et paramètres vectoriels

La configuration de Qdrant Cloud est plus simple que vous ne le pensez.
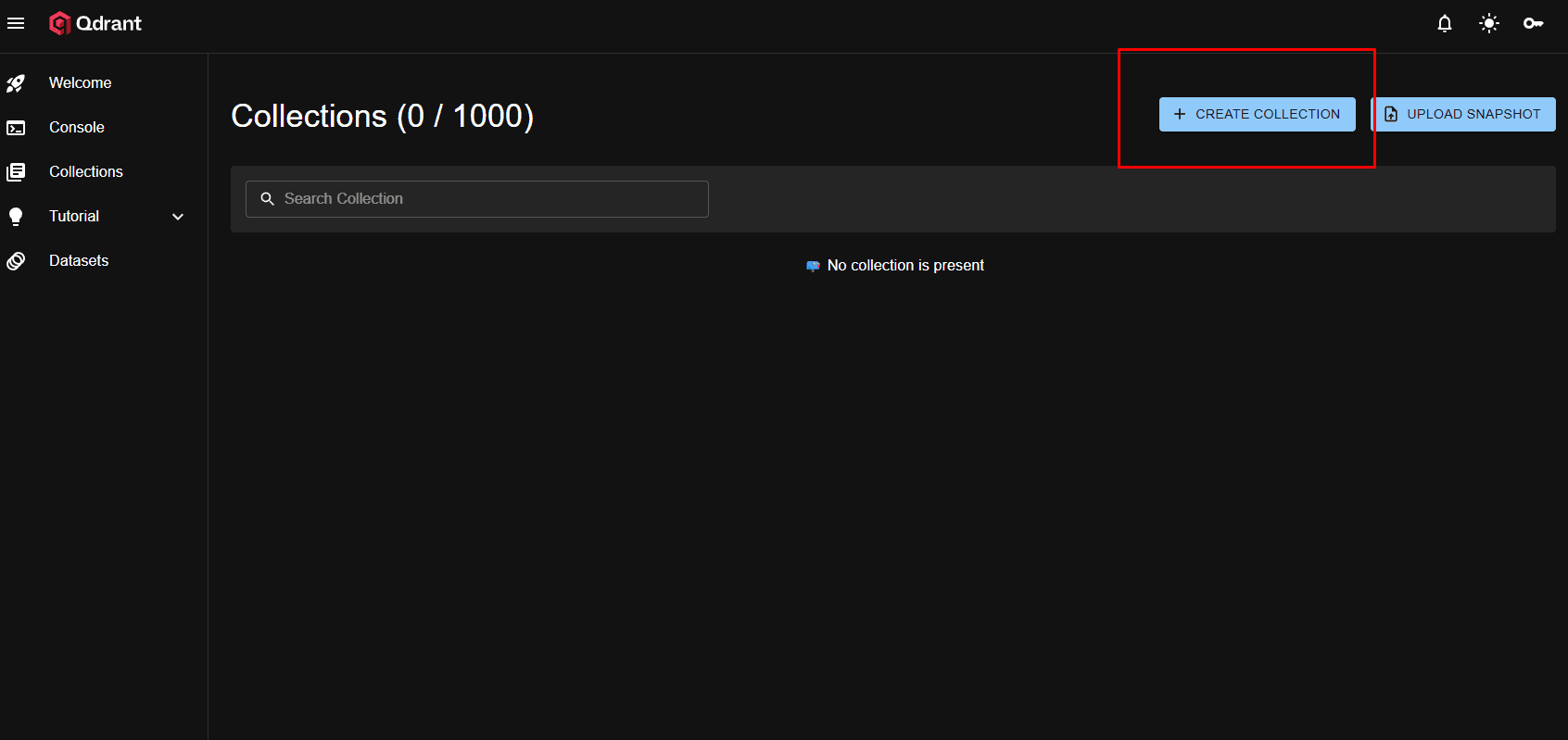
Créez une nouvelle collection directement depuis l'interface Qdrant Cloud ou laissez n8n la créer automatiquement lors de la première insertion (recommandé pour les débutants).
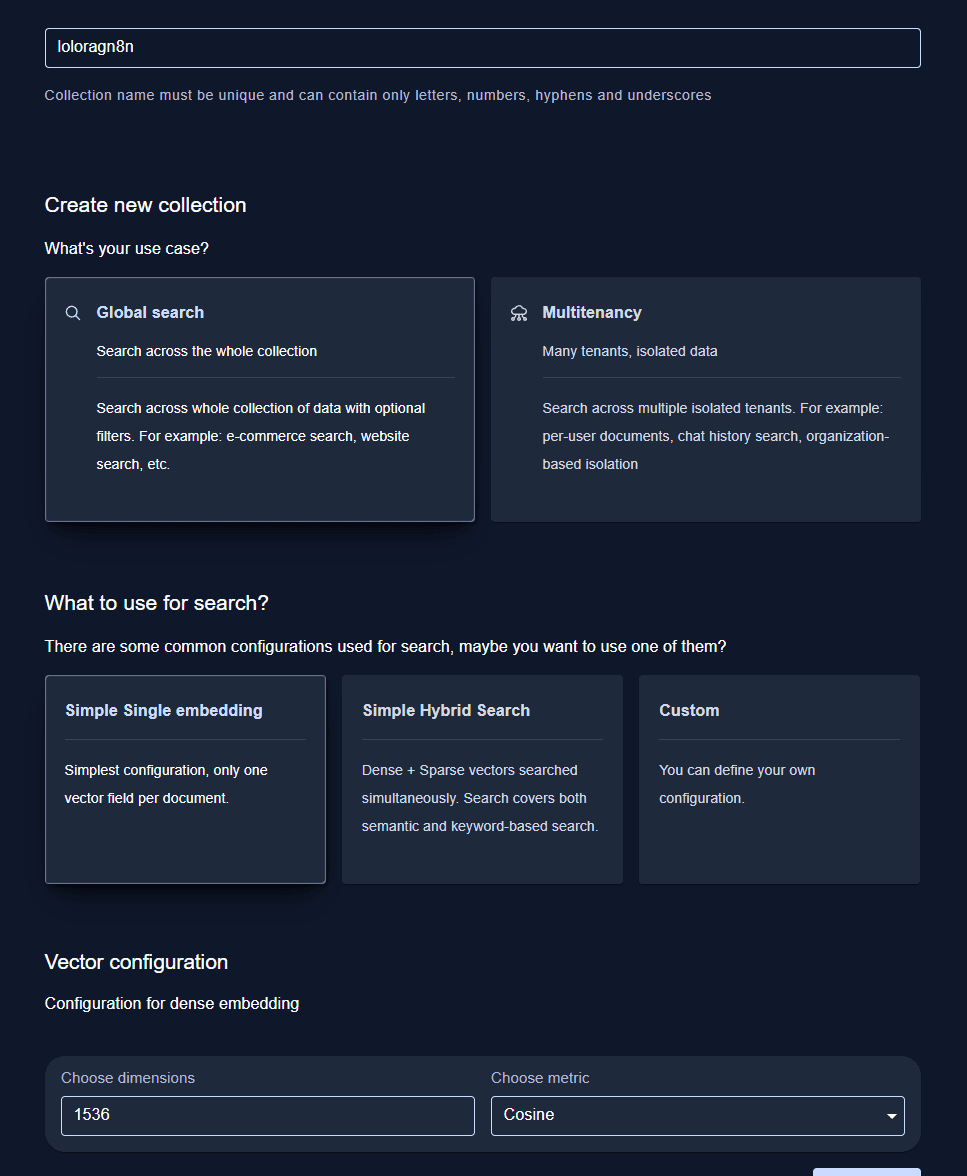
Si vous créez manuellement votre collection, voici les paramètres essentiels à comprendre :
Paramétrez la distance de similarité (metric) : choisissez "Cosine" dans 99% des cas. C'est le standard pour comparer du texte. La distance cosine mesure l'angle entre deux vecteurs - plus l'angle est petit, plus les documents sont similaires sémantiquement. Elle renvoie des valeurs entre -1 et 1, où 1 signifie "parfaitement identiques" et -1 "totalement opposés". Les alternatives (Dot Product, Euclidean) sont rarement nécessaires pour un RAG classique.
Définissez la dimension des vecteurs selon votre modèle d'embedding :
1536 pour
text-embedding-3-smalld'OpenAI (celui que je conseille dans 90% des cas et celui qu'on va utiliser dans ce tutoriel)3072 pour
text-embedding-3-larged'OpenAI1024 pour
mxbai-embed-largeavec Ollama768 pour des modèles plus légers comme
all-MiniLM-L6-v2
⚠️ Attention cruciale : cette dimension doit correspondre exactement à celle produite par votre modèle d'embeddings. Une erreur ici et votre système ne fonctionnera pas.
Dans n8n, configurez le nœud "Qdrant Vector Store" avec trois informations clés :
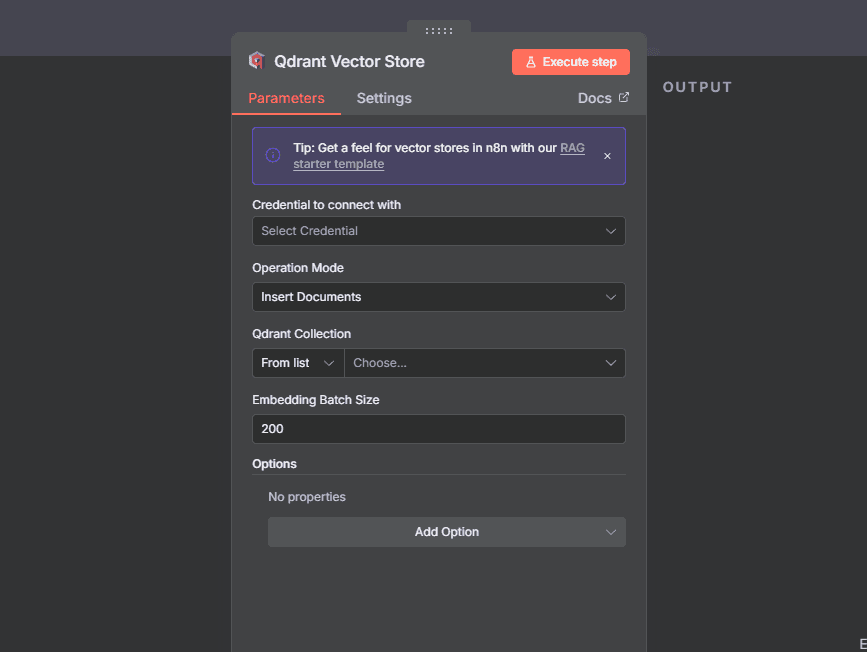
URL du cluster : copiez l'URL complète depuis votre dashboard Qdrant Cloud (avec le port :6333)
Clé API : collez la clé générée précédemment (via credentials dans n8n pour plus de sécurité)
Nom de la collection : donnez un nom explicite comme "knowledge_base" ou "docs_entreprise"
Créez une credential Qdrant dans n8n :
Allez dans Settings > Credentials > New Credential
Cherchez "Qdrant API"
Renseignez votre URL et votre API Key
Sauvegardez
Qdrant Cloud s'occupe automatiquement de la scalabilité, des backups et de la haute disponibilité. Vous n'avez qu'à vous concentrer sur l'alimentation de votre base avec vos documents. L'interface web de Qdrant Cloud vous permet également de visualiser vos collections, voir le nombre de vecteurs stockés, et même faire des recherches de test - très pratique pour débugger.
Découper et vectoriser vos documents
Cette étape transforme vos documents bruts en données exploitables par l'IA. Le processus de splitting détermine comment vos documents seront découpés. Je recommande le "Recursive Character Text Splitter" qui découpe intelligemment en respectant la structure du texte.
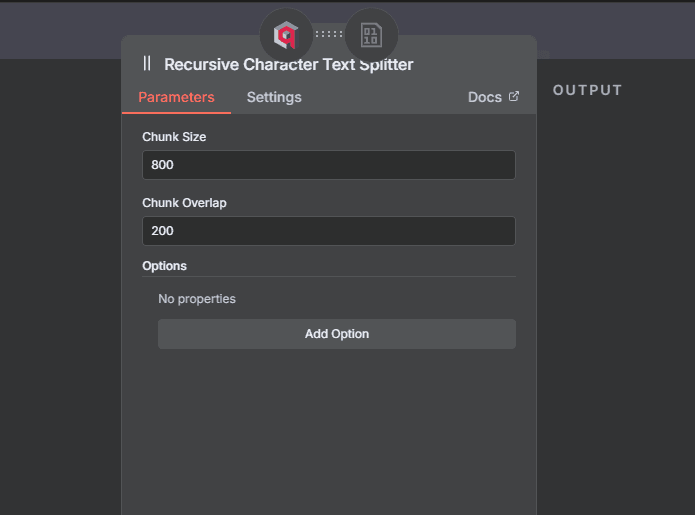
Configurez la taille des chunks : 200-500 caractères pour des réponses précises et courtes, 500-1000 pour des contextes plus riches. Le chunk_size de 200 avec un chunk_overlap de 50 fonctionne bien pour la plupart des cas d'usage. L'overlap permet de ne pas perdre de contexte entre deux morceaux.
Trop de temps perdu sur des processus manuels ?
Découvrez comment mes clients économisent 20h par semaine
4,5
+30 clients accompagnés comme :

Folk

Luneos


Piloterr
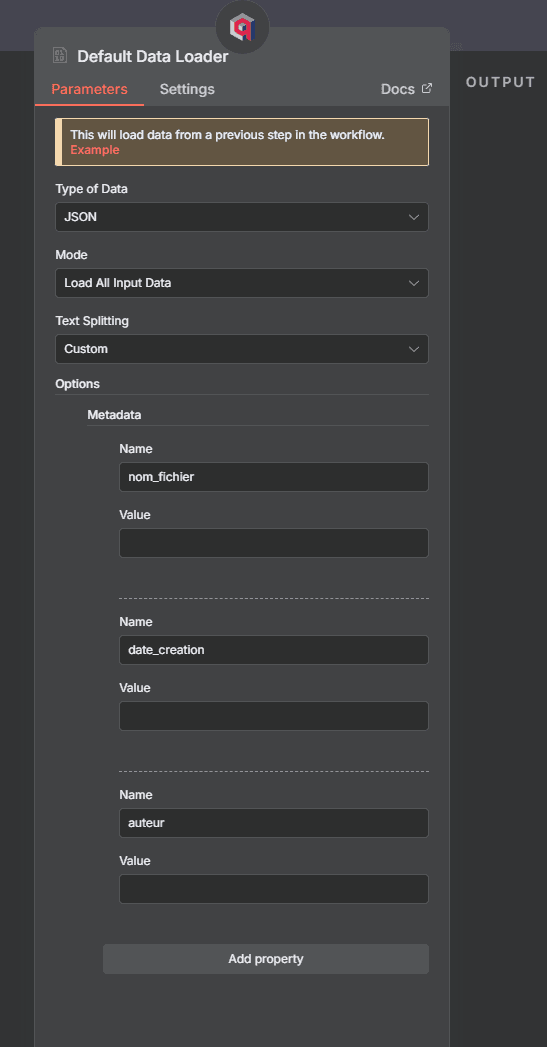
Ajoutez des métadonnées à vos documents : nom du fichier, date de création, auteur, département... Ces métadonnées permettront de filtrer vos recherches plus tard ("trouve-moi les documents du service commercial créés après janvier 2025").
Dans votre workflow n8n, créez le flux suivant :
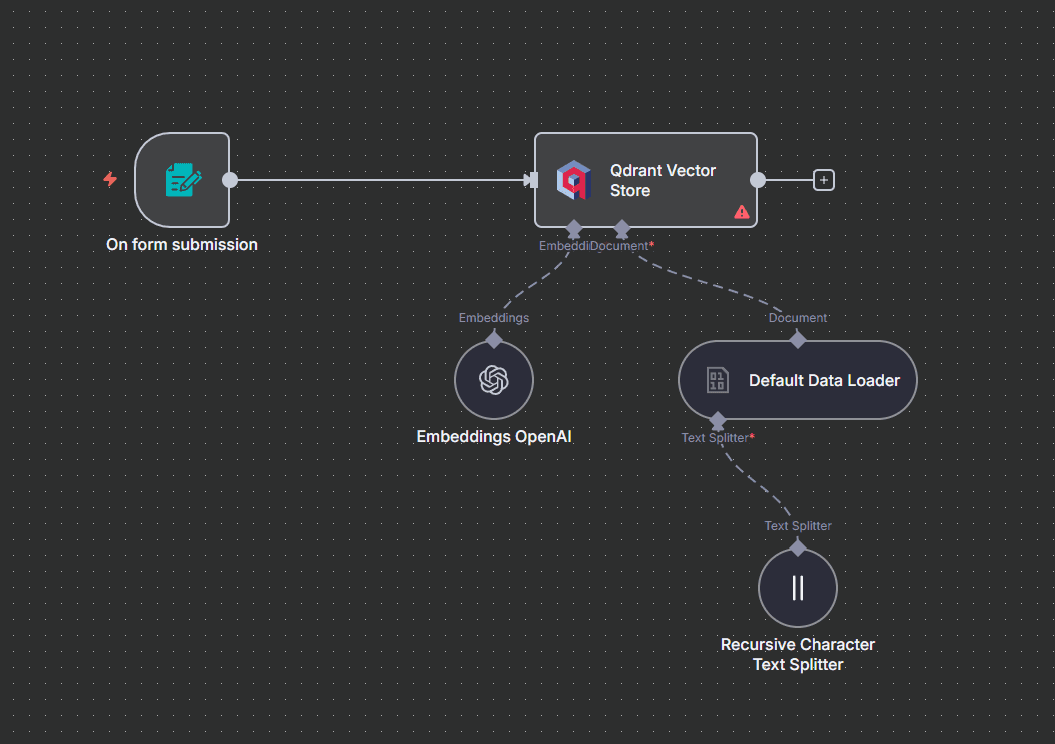
Trigger (Form Trigger pour upload de fichiers)
Default Data Loader (charge le PDF/document)
Text Splitter (découpe en chunks)
Embeddings (OpenAI pour ma part avec
text-embedding-3-small)Qdrant Vector Store en mode "Insert"
Exécutez ce workflow pour chaque document à ajouter à votre base de connaissances.
Créer l'Agent de Conversation IA
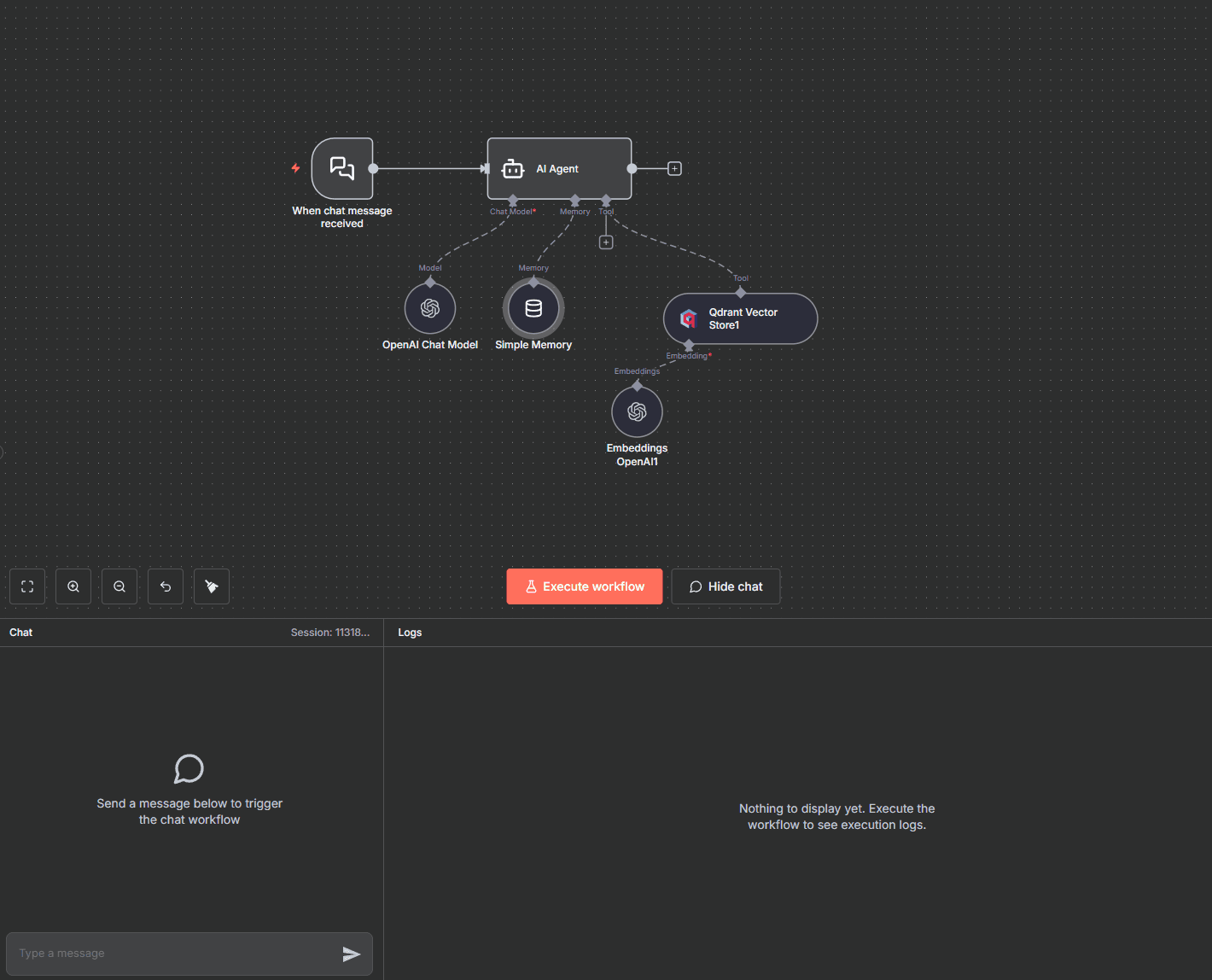
Maintenant que vos documents sont indexés, construisons le chatbot. Configurez le Chat Trigger dans n8n pour créer l'interface de discussion. Ce nœud génère automatiquement une URL de chat accessible dans votre navigateur.
Ajoutez l'AI Agent qui orchestrera la conversation. Dans les options du système, définissez un prompt system clair : "Tu es un assistant expert qui répond uniquement en se basant sur la documentation fournie. Si tu ne trouves pas l'information dans les documents, dis-le clairement." Le mieux c'est de lui dire qu'il à accès a un outil "Qdrant Vector Store".
Connectez votre modèle de langage : Ollama Chat Model (pour Llama ou Mistral) ou OpenAI Chat Model (pour GPT). Configurez la température (0.3-0.7 pour des réponses factuelles, plus haut pour de la créativité). Pour ce tuto je choisirais gpt-4.1-mini
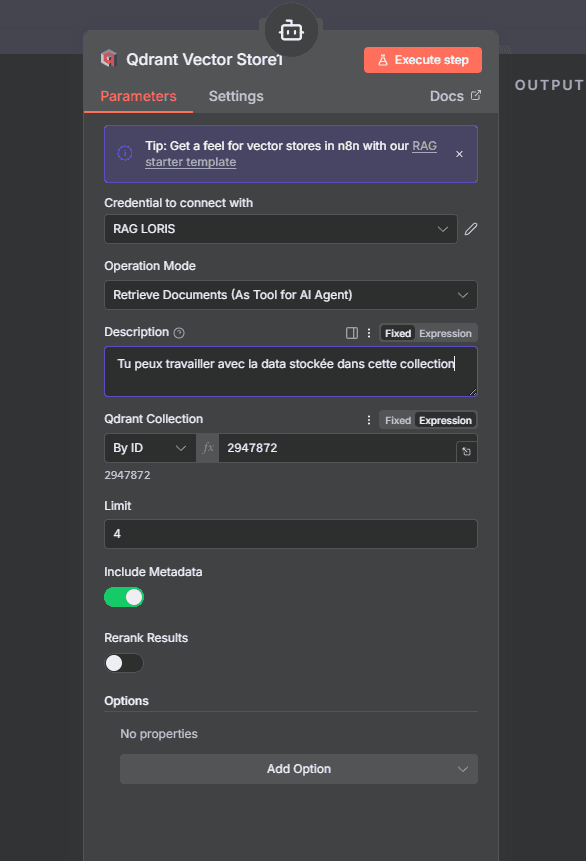
Intégrez Qdrant comme outil de retrieval : utilisez le nœud "Qdrant Vector Store" en mode "Retrieve as Tool". Donnez-lui un nom descriptif comme "knowledge_base" et une description claire : "Récupère des informations depuis la documentation de l'entreprise pour répondre aux questions".
Ajoutez une mémoire conversationnelle avec le nœud "Simple Memory" ou "Window Buffer Memory" pour que votre chatbot se souvienne des échanges précédents dans la conversation.
Optimiser les Requêtes et la qualité des réponses
La qualité de votre RAG dépend fortement de ces optimisations. Configurez le nombre de résultats retournés (topK) : 3-5 chunks généralement suffisent. Plus vous en récupérez, plus vous donnez de contexte à l'IA, mais attention à ne pas dépasser la limite de tokens.
Définissez un score de similarité minimum (threshold) : 0.7-0.8 pour filtrer les résultats peu pertinents. Si aucun document ne dépasse ce seuil, le système indiquera qu'il n'a pas trouvé d'information pertinente.
Testez différents modèles d'IA : Llama 3.2 (rapide, local), Mistral (bon compromis), GPT-4 (meilleure compréhension), GPT-3.5 (plus économique). Chaque modèle a ses forces : GPT-4 excelle en compréhension nuancée, Llama en rapidité.
Améliorez vos prompts système : spécifiez le format de réponse souhaité, le ton, la longueur. Exemple : "Réponds de manière concise en citant toujours la source du document utilisé. Si plusieurs documents contradictoires existent, mentionne-le."
Connecter plusieurs sources de données
Un RAG vraiment puissant agrège plusieurs types de sources. Créez des workflows parallèles pour différentes sources : un pour les PDF, un pour les emails (via Gmail API), un pour vos bases Notion ou Airtable.
Utilisez les métadonnées pour identifier les sources : ajoutez un champ "source_type": "email" ou "source_type": "pdf" lors de l'ingestion. Cela permet de filtrer par type dans vos requêtes.
Configurez des schedules pour la mise à jour automatique : exécutez le workflow d'ingestion chaque nuit pour indexer les nouveaux documents, ou utilisez des webhooks pour une indexation en temps réel dès qu'un document est créé.
La beauté de n8n réside dans cette flexibilité : vous pouvez connecter Google Drive, Dropbox, votre CRM, vos tickets de support... tout devient interrogeable via votre chatbot.
Cas d'usage pratiques du RAG n8n
Support client intelligent : indexez votre base de connaissances, vos FAQs, vos tickets résolus. Votre équipe support interroge le RAG avant de répondre aux clients, garantissant des réponses cohérentes et précises.
Onboarding des nouveaux employés : tous vos guides d'onboarding, procédures internes, organigrammes... accessibles via chat. Le nouvel arrivant pose ses questions et obtient instantanément les bonnes informations.
Veille concurrentielle : stockez vos rapports de marché, analyses concurrentes, études sectorielles. Interrogez votre RAG pour extraire des insights rapidement : "Quelles sont les stratégies pricing de nos concurrents ?"
Conformité et documentation légale : centralisez vos documents de conformité, contrats types, réglementations. L'équipe juridique peut vérifier rapidement les clauses applicables à une situation donnée.
Conclusion : Votre prochaine étape vers l'IA conversationnelle
Créer un RAG sur n8n transforme radicalement la façon dont vous accédez à vos connaissances d'entreprise. Ce système intelligent élimine les recherches fastidieuses, réduit la dépendance aux experts internes, et garantit que l'information critique est toujours à portée de question.
Commencez petit : indexez d'abord vos 10-20 documents les plus consultés, testez le système avec votre équipe, recueillez les retours. Puis étendez progressivement à l'ensemble de votre documentation. L'investissement initial en vaut largement la peine : vous créez un actif numérique qui devient plus précieux au fil du temps.
La combinaison n8n + Qdrant + OpenAI/Ollama offre un équilibre parfait entre puissance, flexibilité et contrôle. Vous n'êtes plus dépendant d'une solution SaaS opaque dont les coûts explosent avec l'usage.
Prêt à automatiser l'accès à vos connaissances ? Commencez par configurer votre environnement n8n dès aujourd'hui, et dans quelques heures, vous discuterez avec votre documentation comme jamais auparavant.
Mes articles les plus récents
Si tu as aimé mon article sur " RAG n8n : Tutoriel complet pour construire votre Chatbot IA" alors tu devrais adorer ses articles :